Implementing bucketMul
in Metal
Below is a simplified version of the main bucketMul function. This function takes dispatch as a parameter, along with model weights, and outputs multiplications into the result.
kernel void bucketMul(
device const half *weights [[buffer(0)]],
device const float2 *dispatch [[buffer(1)]],
device float *result [[buffer(2)]],
constant uint *dispatchSize [[buffer(3)]],
uint bucketID [[thread_position_in_grid]]) {
float myVal[16] = {0};
for (uint r=0; r<dispatchSize; r+=1) {
float2 d = dispatch[rowOffset]; // d[0] is weight, d[1] is rowId
half w = weights[int(d[1]) + bucketID]; // Get weight based on dispatch
float v = d[0]*float(w); // Perform multiplication
ushort pos = as_type<ushort>(w) & 15; // Get position for the result
for (int i=0; i<16; i++) {
myVal[i] += (pos == i) ? v : 0;
}
}
// Store results in the output buffer
for (int i = 0; i<16; i++) {
result[myOff + i] = myVal[i];
}
}
Readers new to GPU programming might wonder, 'How does it work?'?
Readers experienced with GPU programming might ask, 'How on earth does it work?'
Basics of Metal
The above code is what's known as a shader function. It is invoked from Swift with a line like this:
wrapper to actual Swift functions - makes for easier reading
gpu.deploy("bucketMulFast",
buffers: [ weightBuckets,
dispatch,
tmpMulVec,
dispatch.size],
threadCount: [ weightBuckets.cols ])
This function is invoked `threadCount` times, each time receiving the same parameters. The only difference is the bucketID, which represents each thread's position in the grid—defined here as [weightBuckets.cols].
Each call gets the same parameters, with the only difference being, in this case - bucketID, which is a thread's position in the grid. Grid in this case is simply [ weightBuckets.cols ].
Each call performs the computations, and writes out the result into the result buffer.
Crucially, Apple's GPUs organize threads into SIMD-groups of 32, simplyfing wildly.
SIMD (Same Instruction, Multiple Data) groups execute all operations in lockstep, performing identical operations but potentially on different data.
There is no need to synchronize the threads within a single group, as they always operate in unison. If one thread encounters an 'if' condition, the others will wait for this condition to resolve before proceeding.
That's it for the basics. If you did any programming in your life, the code should be quite simple to understand:
- it fetches a row from dispatch: each row has the value, and an id of a bucket row - we'll be multiplying the value by the buckets in the bucket row
- for every bucketID, it grabs it's weight, it grabs the position from the least significant bits (& 15), and it multiplies the rest by the value, putting it into local memory (which is super-fast to access)
- finally, it outputs the result into the device memory
Why BucketMul works fast
This whole section needs rewriting and feedback. Please reach out if you know anything about Metal programming. Now, this may be obvious to some, but it wasn't obvious for me. Apple's documentation is lacking, disassembly not easily accessible, and I believe I may have bent some rules while crafting the code shown above.
A better explaination will be most welcome.
Here are my theories on why such straightforward code is effective:
- Dispatch Load: The data involved is minimal and gets cached quickly, reducing the need for extensive coordination during loading.
- Weights Load: Reads are implicitly synchronized, with SIMD-group threads loading adjacent elements, allowing high-speed, consecutive reads. We're going against every known manual that says the reads should be consecutive within a single thread, not across threads - but somehow it seems to work?
- myVal[i] loop An unrolled micro-loop uses cheap three-way operators, minimizing random memory access. A simpler approach like 'myVal[j] += v' didn't work if I checked correctly. - myVal storage and speed: - this is the biggest mystery to me! - it seems it's the main bottleneck in calculations - increasing size of myVal (say to 32) lowers the speed of operation twice - keeping the size intact, but using just a fraction of the values speeds up the operation twice (!) - if you change & 15 to & 7, or modify underlying data to be in a smaller range (!!!), you will get a performance boost - where is myVal stored and at what form? it won't fit the registers, it doesn't go to device memory, so I guess some sort of an intermediate cache? If anyone can shine light at it, I will appreciate it
The storage of myVal may also be a reason why bucketMool seems to have a higher speed on M3 compared to M2/M1. M3 has their cache/registry structure reorganised.
Why buckets are sized 16.
If we switched from 16 to 32, we lose an extra bit for storing weights (can be avoided - see next chapter), and above all - the speed gets 2x lower, so we can't go that way.
The higher the bucket size, the more precise the bucket sorting (see previous chapter). So ideally, we'd like as large of a bucket as possible.
If we go into a lower bucket size, say 8, the memory ordering won't be as precise, and we'll need higher effort for the same result. With Q8 that's what we needed to do though. Also, if I remember correctly - with buckets sized 8 - execution slowed down in other places and we ended up in the same place as before - speed-wise.
Overhead performance challenges
This is my first program that tackles GPU development, and I could seriously use help here.While the bucketMul is implemented fast enough - reaching parity with Apple's MPS at 50-70% effort, the rest of the inference process has an overhead that I have no idea how to fix. It definitely is fixable, since Llama.cpp and others don't seem to have it.
In the GPU profiler, I can see holes between certain kernel invocations, and I cannot figure out where they come from.
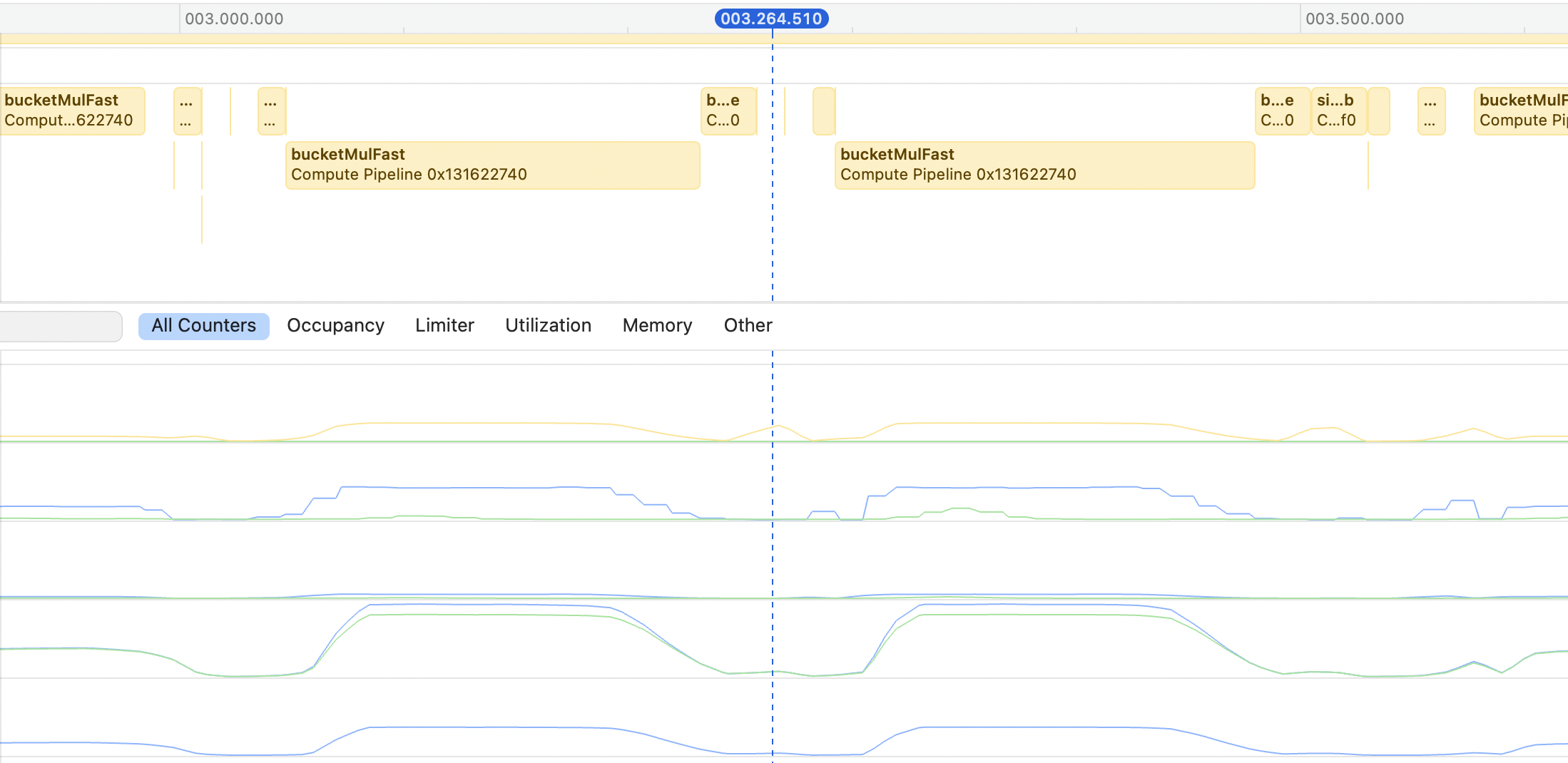
I think these holes sum up to 15ms overhead to every token generation. In my case, even with multiplications set to zero, I can generate max ~60tps on my laptop. If you have an idea on how to fix that, please I beg shoot me an e-mail: kolinko@gmail.com.
It has probably something to do with the way I call commandQueue etc, or because of the buffers are hazard-tracked. But I spent days trying to figure it out, and just cannot find the reason. The relevant code is in here, and here.
Without this, we have a Ferrari engine in a Fiat body here - no simple way to show the results and do serious benchmarking.
Quality issues even at 100% effort
May actually work fine. I began benchmarking KL distance now, and it seems at effort 100% it's giving the same results as the original. Will post an update soon. -- TK 21.04.2024 The second challenge is that the current implementation seems just broken. It used to deliver results that were very close to the original Mistral, and Mixtral used to work. Right now Mistral is not as good as it used to be, and Mixtral barely works. I'm at my wits' end trying to debug it all - if anyone knows enough about both GPU debugging and LLM implementations, I would appreciate any help here.
Could bucketMul run even faster?
Could we improve bucketMul to get to full 100% memory bandwidth read speed? Right now it's around 50-70%. I tried simdgroup-coordinated reads and other tricks (you can see them in the helpers/wild sources), but failed to write anything better than this.
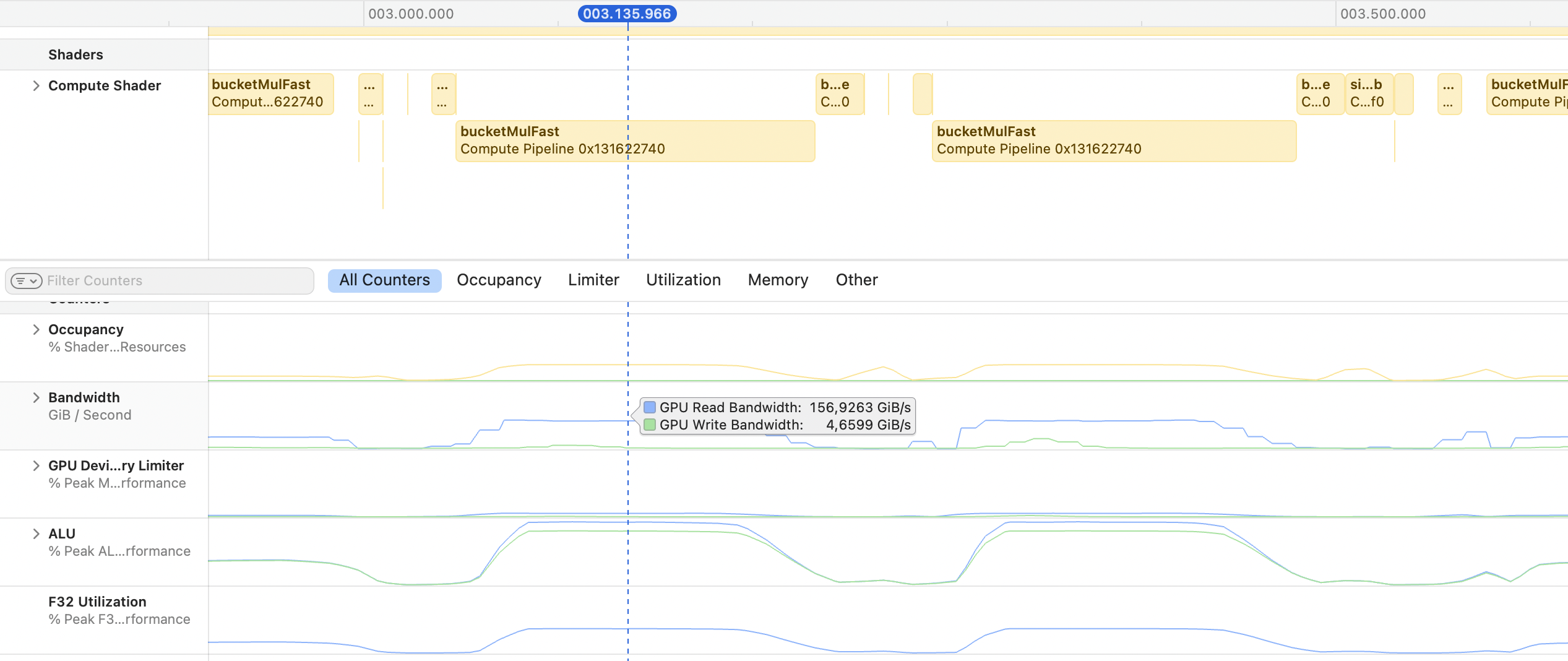 Half the max practical memory read speed. Limited by ALU. It's still amazing, but there may be room for improvement.
Half the max practical memory read speed. Limited by ALU. It's still amazing, but there may be room for improvement.
Unlike the overhead delays, this is not a priority.
Optimisation for different matrix sizes
The current implementation is optimised for a matrix shape of 4096x14336 (w1 and w3). It can be just as fast on 14336x4096 and 4096x4096 , but needs hand-tuning the number of threads/groups for every case. An easy fix, just needs some engineering time.
Dispatch non-determinism
It's a minor issue, but difficult to fix. Dispatch uses atomic loats to generate ids. It doesn't affect speed much, but it causes the whole token generation to be nondeterministic. It is a bit irritating during testing, but the overall effect is just a slight unpredictibality of the output. Fixing this is a low priority.
Where do we go from here?
- MoE, Quantization and the others.
- Pesky details (or: Help Needed!)
At any time
And of course...
- Citations, notes and so on